Pandas进阶及统计分析
基本数据对象及操作
数据清洗
数据合并及分组
透视表
基本数据对象及操作
- 2008年由Wes McKinney创建
- 一个强大的分析结构化数据的工具集
- 基础是NumPy,提供了高性能矩阵的运算
链接:pandas
Series
- 类似一维数组的对象
- 通过list构建Series
- ser_obj = pd.Series(range(10))
1 | import pandas as pd |
结果:
1 | <class 'pandas.core.series.Series'> |
- index对象
1 | countries_s.index #index对象 |
结果:
1 | RangeIndex(start=0, stop=3, step=1) |
- 看series和array的关系
1 | countries_s.values #可以看出series和array的关系 |
结果:
1 | array(['中国', '美国', '澳大利亚'], dtype=object) |
- 由数据和索引组成
- 索引在左,数据在右
- 索引是自动创建的
1 | numbers = [4, 5, 6] |
结果:
1 | 0 4 |
- 获取数据和索引
- ser_obj.index , ser_obj.values
- 预览数据
- ser_obj.head(n)
1 | country_dicts = {'CH': '中国', |
结果:
1 | Code |
- 处理缺失数据
- 如object—-> None, float—–>NaN
1 | countries = ['中国', '美国', '澳大利亚', None] |
结果:
1 | 0 中国 |
- Series索引数据
1 | country_dicts = {'CH': '中国', |
结果:
1 | Code |
- 通过索引判断数据是存在
1 | # 通过索引判断数据是存在 |
结果:
1 | True |
- 几种获取数据的方法
1 | #几种获取数据的方法 |
结果:
1 | iloc: 中国 |
- 向量化操作
1 | #通过时间的对比来观察向量化操作的优势 |
结果:
1 | 0 610 |
- 通过时间的对比,来突出向量化操作可以缩短时间
1 | %%timeit -n 100 # %%只能在jyputer上使用 #对所有数据进行求和 |
结果:
1 | 656 µs ± 63.9 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) |
- 对比上面循环操作,下方的整体操作可以大幅度缩小运行时间
1 | %%timeit -n 100 |
结果:
1 | 149 µs ± 40.3 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) |
DataFrame
链接:dataframe
- 类似多维数组/表格数据(如,excel,R中的data.frame)
- 每列数据可以是不同的类型
- 索引包括行索引(index)和列索引(label)
- 创建Dataframe
1 | import pandas as pd |
- 注意在jupyter中使用print和不使用print的区别
1 | # 注意在jupyter中使用print和不使用print的区别 |
- 下面为print打印的结果
1 | Area Happiness Rank Language Name |
- 下面为直接df后出来的图表
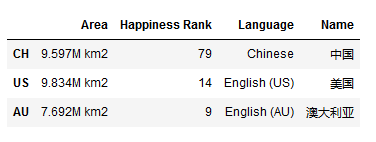
- 添加值(values)
1 | # 添加数据 |
结果:
1 | Area Happiness Rank Language Name Location |
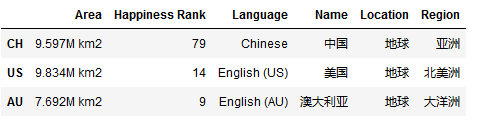
- Dataframe索引
注意:从DataFrame中取出的数据进行操作后,会对原始数据产生影响。为了保证不对原始数据产生影响,应该使用copy()产生一个副本。在副本上进行操作。
1 | # 行索引 |
结果:
1 | loc: |
- 列索引
1 | # 列索引 |
结果:
1 | CH 9.597M km2 |
- 获取不连续的列数据
1 | # 获取不连续的列数据 |
结果:
1 | Name Area |
- 混合索引
1 | # 混合索引 |
结果:
1 | 先取出列,再取行: |
- 转换行和列
1 | # 转换行和列 |
结果:
1 | CH US AU |
- 删除数据
1 | print(df.drop(['CH'])) |
结果:
1 | Area Happiness Rank Language Name Location Region |
- inplace的参数
1 | print(df.drop(['CH'], inplace=True)) |
结果:
1 | Area Happiness Rank Language Name Location Region |
- 删除列时,对axis的指定,0和1要区别(1是对列操作,0是对行操作)
1 | # 如果需要删除列,需要指定axis=1 |
结果:
1 | Happiness Rank Language Name Location Region |
- 也可以直接使用del关键字进行删除
1 | # 也可直接使用del关键字 |
结果:
1 | Area Happiness Rank Language Location Region |
DataFrame的操作
1 | df['Happiness Rank'] |
结果:
1 | US 14 |
- 对取出的数据进行操作
1 | # 注意从DataFrame中取出的数据进行操作后,会对原始数据产生影响 ###注意copy和不copy的区别 |
结果:
1 | US 16 |
- 对数据进行copy和非copy的之后的区别
1 | # 注意从DataFrame中取出的数据进行操作后,会对原始数据产生影响 |
结果:
1 | US 18 |
索引操作总结
Pandas的索引可以归纳为3中:
.loc,标签索引
.iloc,位置索引 (loc与iloc主要用于行索引)
.ix,标签与位置混合索引(先按标签索引尝试操作,然后再按位置索引尝试操作)
注意:
1
21. DataFrame索引时可将其看作ndarray操作
2. 标签的切片索引是包含末尾位置的数据读取
pd.read_csv()
index_col:指定索引列
usecols:指定需要读取的列
- 对于csv文档的基本操作
1 | # 加载csv文件数据 |
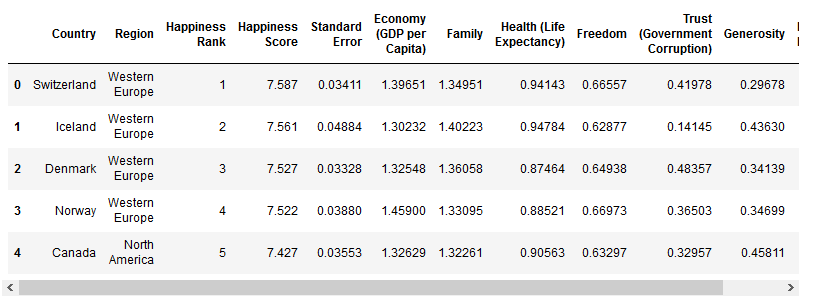
1 | print(report_2015_df.info()) #查看相关数据 |
结果:
1 | <class 'pandas.core.frame.DataFrame'> |
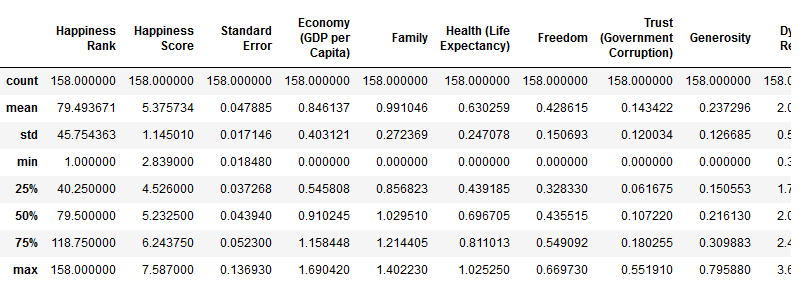
- 对数据进行均值、方差等数据描述
1 | report_2015_df.describe() #对数据进行统计(每列) |
- 查看末尾的数据
1 | report_2015_df.tail() #查看末尾的数据 |
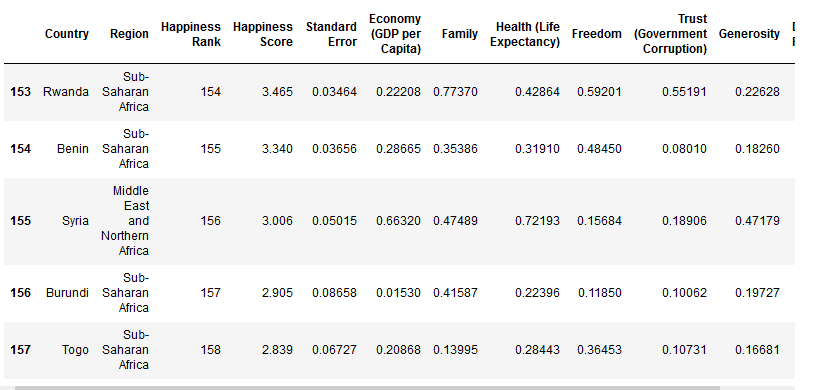
索引对象Index
Series和DataFrame中的索引都是Index对象
- 不可变(保证了数据的安全)
- 常见的Index种类
- Index
- Int64Index
- MultiIndex,‘层次’索引
- DatetimeIndex,时间戳类型
- 重置索引 reset_index(),将索引重新赋值为0-1
- 重命名列名:df.rename(columns = {old_col:new_col},inplace = True)
1 | # 使用index_col指定索引列 |
- 打印列名和行名
1 | print('列名(column):', report_2016_df.columns) |
结果:
1 | 列名(column): Index(['Region', 'Happiness Rank', 'Happiness Score'], dtype='object') |
- index是不可以变的
1 | # 注意index是不可变的 |
- index的重置
1 | # 重置index |
1 | report_2016_df.head() |
- 重命名列名
1 | # 重命名列名 |
1 | # 重命名列名,注意inplace的使用 |
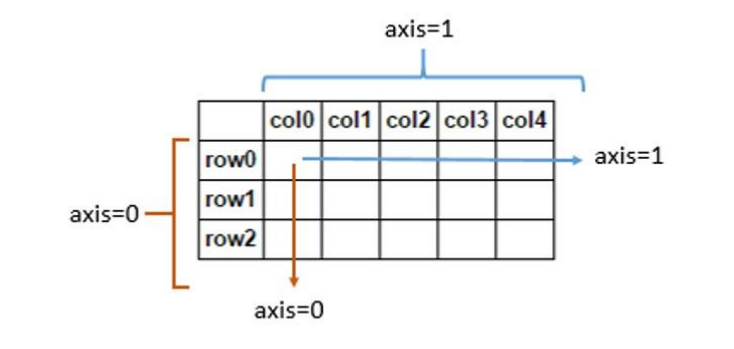
- 注意并且重要:轴的方向
- axis = 0 ,表示纵向计算(计算整行的数–每列每列)
- axis = 1 ,表示横向计算(计算整列的数–每行每行)
Boolean Mask
1 | report_2016_df.head() |
1 | # 过滤 Western Europe 地区的国家 |
- 过滤数据
1 | # 过滤 Western Europe 地区的国家 |
结果:
1 | 0 False |
- 叠加boolean mask得到结果
1 | # 叠加 boolean mask 得到最终结果 |

1 | # 熟练以后可以写在一行中 |
层级索引
- MulitIndex对象
- set_index([‘a’,’b’],inplace = True),注意a,b的先后顺序
- 选取子集
- 外层选取ser_obj.loc[‘outer_index’]
- 内层选取ser_obj.loc[‘out_index’,’inner_index’]
- 常用于分组操作、透视表的生产等
- 交换分层顺序
- swaplevel()
- 排序分层
- sort_index(level = )
1 | report_2015_df.head() |
- 设置层级索引
1 | # 设置层级索引 |
1 | # 只访西欧的国家,行索引,外层索引 |
- 内层索引
1 | # 内层索引 |

- 交换分层顺序
1 | # 交换分层顺序 |
1 | # 排序分层 |
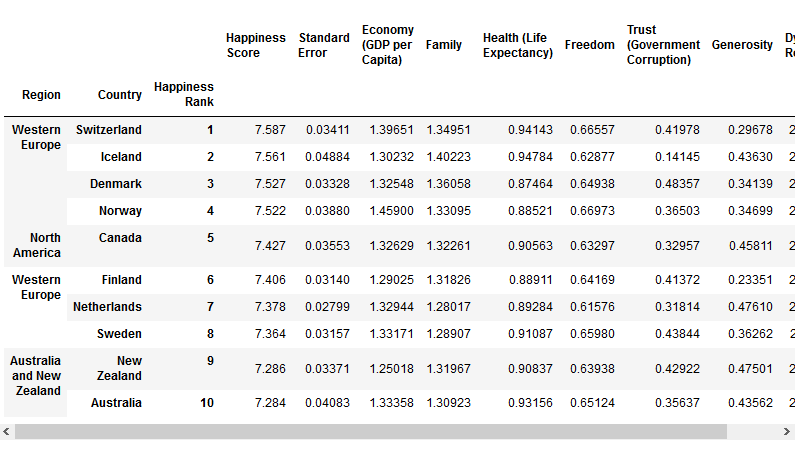
数据清洗
- 是数据分析关键的一步,直接影响之后的处理工作
- 数据该如何调整才能适用于接下来的分析和挖掘
- 是一个迭代的过程,实际项目中可能需要不止一次地执行这些清洗操作
处理缺失数据
- 判断数据缺失,ser.obj.isnull(),df_obj.insull(),相反操作为notnull()
- 处理缺失数据
- df.fillna(),df.dropna()
- df.ffill(),按之前的数据填充
- df.bfill(),按之后的数据填充
-项目中使用ffill或bfill时,注意数据的排列顺序
1 | import pandas as pd |
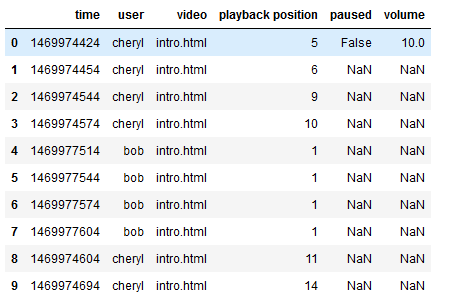
- 判断数据是否缺失
1 | #判断数据是否缺失 |
结果:
1 | <class 'pandas.core.frame.DataFrame'> |
- 查看缺失值
1 | log_data.isnull().head(10) #True表示缺失,False表示没有缺失 |

- 判断某一列是否缺失
1 | log_data['paused'].isnull().head(5) #判断某一列是否缺失 |
结果:
1 | 0 False |
- 数据过滤处理
1 | # 取出volume不为空的数据,数据过滤处理 |
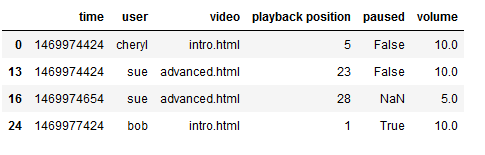
- 进行层级索引
1 | log_data.set_index(['time', 'user'], inplace=True) #进行层级索引,先时间戳再user |
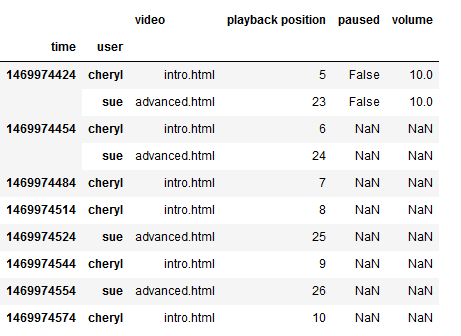
- 填充缺失值
1 | log_data.fillna(0).head(10) #用0将缺失的值全部填充 #inplace = true就会让对原来数据产生影响 |
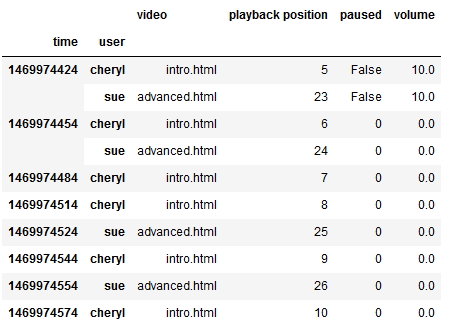
- 删除空数据
1 | log_data.dropna() #删除空数据 |
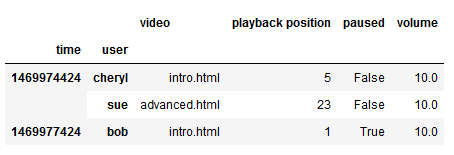
- 以上一个数据进行填充
1 | log_data.ffill().head(10) #按之前的数据填,指的就是上一个数据填 |
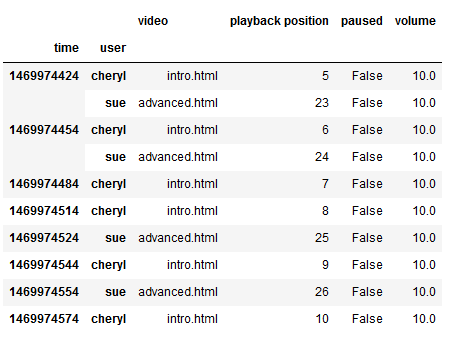
- 按之后的数据进行填充
1 | log_data.bfill().head(10) #按之后的数据填充 |
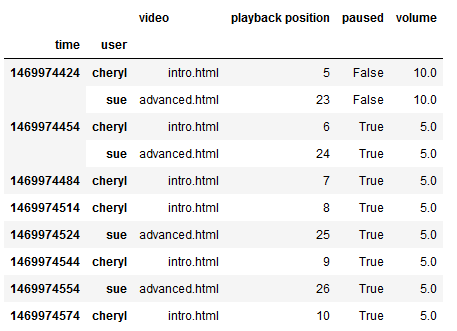
数据变形
- 处理重复数据
- 判断数据是否重复,duplicated()
- 去除重复数据,drop_duplicates(),可指定列及如何保留数据
- 使用函数或map转化数据,通常根据字典进行数据转化
- 替换值,replace()
- 离散化和分箱操作,put.cut(),返回Categorical对象
- 哑变量操作,pd.get_dummies()
- 向量化字符串操作
- 字符串列元素中是否包含子字符串,ser_obj.str.contains()
- 字符串列切片操作,ser_obj.str[a:b]
1 | #处理重复数据 |
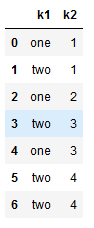
- 判断数据是否重复
1 | # 判断数据是否重复 |
结果:
1 | 0 False |
- 去除重复数据
1 | # 去除重复数据 |

- 若col索引不存在会自动添加列索引以及值
1 | data['v1'] = range(7) #如果col的索引不存在会自动添加列索引以及值 |

- 去除列的重复数据
1 | # 去除指定列的重复数据 |
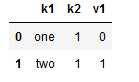
- 保持后面的那个数据
1 | data.drop_duplicates(['k1', 'k2'], keep='last') #通过两列去重复,keep指的是保持最后的那个数据 |

- 使用函数或map转换数据
1 | #使用函数或map转化数据 |
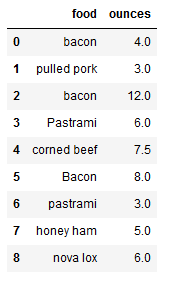
- 添加一列
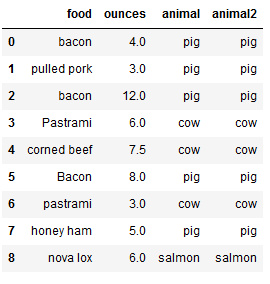
1 | # 添加一列,用于指定食物的来源 |
1 | # 使用map() |
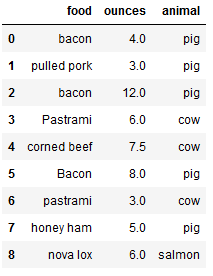
- 使用匿名函数
1 | # 使用方法,使用lambda |
- 用replace替换(将-999替换成为空值)
1 | #替换值replace |
结果:
1 | 0 1.0 |
1 | import numpy as np |
结果:
1 | 0 1.0 |
- 将-999,-1000都替换为空值
1 | # 将-999,-1000都替换为空值 |
结果:
1 | 0 1.0 |
- 将-999,-1000分别替换为空值和0
1 | # 将-999,-1000分别替换为空值和0 |
结果:
1 | 0 1.0 |
- 用字典来数值替换
1 | #用字典来数值替换 |
结果:
1 | 0 1.0 |
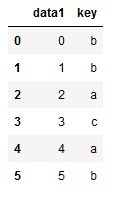
- 离散化和分箱操作
1 | #离散化和分箱操作 |
1 | cats = pd.cut(ages, bins) |
1 | <class 'pandas.core.categorical.Categorical'> |
- Categorical对象
1 | # Categorical对象 |
结果:
1 | [(18, 25], (18, 25], (18, 25], (25, 35], (18, 25], ..., (25, 35], (60, 100], (35, 60], (35, 60], (25, 35]] |
- 获取分箱编码
1 | # 获取分箱编码 #类别型特征处理的时候可以用分箱操作 |
结果:
1 | array([0, 0, 0, 1, 0, 0, 2, 1, 3, 2, 2, 1], dtype=int8) |
- 返回分箱边界索引
1 | # 返回分箱边界索引 |
结果:
1 | IntervalIndex([(18, 25], (25, 35], (35, 60], (60, 100]] |
- 统计箱中元素的个数
1 | # 统计箱中元素的个数 |
结果:
1 | (18, 25] 5 |
- 带标签的分箱
1 | # 带标签的分箱 #将分箱用名字来代替,类别型的特征 |
1 | cats.get_values() #获取数据的值 |
结果:
1 | array(['Youth', 'Youth', 'Youth', 'YoungAdult', 'Youth', 'Youth', |
- 统计箱中元素的个数
1 | # 统计箱中元素的个数 |
结果:
1 | Youth 5 |
- 哑变量操作
1 | #哑变量操作(sklearn里面是one-hot) |
1 | #哑变量 |

- 向量化操作
1 | #向量化操作 |
结果:
1 | Dave dave@google.com |
- 查看关键字
1 | data.str.contains('gmail') #关键字是否含有 |
结果:
1 | Dave False |
- 取前5个数据
1 | data.str[:5] #取前5个数据 |
结果:
1 | Dave dave@ |
- split操作
1 | split_df = data.str.split('@', expand=True) #expand默认是false,如果是true就分成两列 |
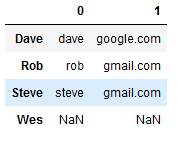
- 进行合并
1 | split_df[0].str.cat(split_df[1], sep='@') #cat是将两个合并,通过@字符 |
结果:
1 | Dave dave@google.com |
数据合并及分组
数据合并(pd.merge)
根据单个或多个键将不同DataFrame的行连接
默认将重叠列的列名作为‘外键’进行连接
- on 显示指定’外键’
- left_on ,左侧数据的’外键’
- right_on,右侧数据的’外键’
默认是’内连接(inner),既结果中的键是交集
how指定连接方式
‘外链接’(outer),结果中的键是并集
‘左连接’(left)
‘右连接’(right)
处理重复列名
suffixes,默认为_x,_y
按索引连接
left_index =True 或 right_index = True
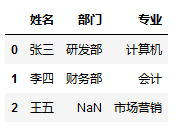
1 | import pandas as pd |
结果:
1 | 姓名 部门 |
- 并集
1 | print(pd.merge(staff_df, student_df, how='outer', on = '姓名')) ##并集 |
结果:
1 | 姓名 部门 专业 |
- 交集
1 | print(pd.merge(staff_df, student_df, how='inner', on='姓名')) #交集 |
结果:
1 | 姓名 部门 专业 |
- 左边数据是完整的
1 | print(pd.merge(staff_df, student_df, how='left', on='姓名')) #左边数据是完整的 |
结果:
1 | 姓名 部门 专业 |
- 右边数据全完整
1 | pd.merge(staff_df, student_df, how='right', on='姓名') ##右边数据全有 |
- 按索引进行合并
1 | # 也可以按索引进行合并 |
结果:
1 | 部门 |
- 按第一个表格的索引合并
1 | print(pd.merge(staff_df, student_df, how='left', left_index=True, right_index=True)) |
结果:
1 | 部门 专业 |
- 当数据中的列名不同时,使用left_on,right_on
1 | # 当数据中的列名不同时,使用left_on,right_on |
结果:
1 | 姓名 部门 |
1 | staff_df.rename(columns={'姓名': '员工姓名'}, inplace=True) |
结果:
1 | 员工姓名 部门 |
- 合并员工姓名和学生姓名
1 | pd.merge(staff_df, student_df, how='left', left_on='员工姓名', right_on='学生姓名') #合并员工姓名和学生姓名 |
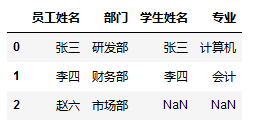
- 当两个数据包含相同的列名,合并后会给列名加后缀加以区别
1 | # 如果两个数据中包含有相同的列名(不是要合并的列)时,merge会自动加后缀作为区别 |
1 | 员工姓名 部门 地址 |
1 | pd.merge(staff_df, student_df, how='left', left_on='员工姓名', right_on='学生姓名') #会自动加后缀区别 |
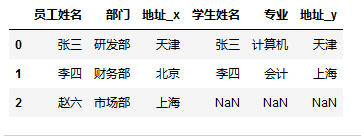
- 可以指定后缀名称
1 | # 也可指定后缀名称 |
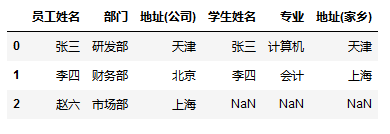
- 也可以指定多列进行合并,找出同一个人的工作地址和家乡地址相同的记录
1 | # 也可以指定多列进行合并,找出同一个人的工作地址和家乡地址相同的记录 |

函数应用
- 可直接使用NumPy的ufunc函数,如abs等
- 通过apply将函数应用到行或列上
- 注意指定轴的方向,默认axis = 0
- 通过applymap将函数应用到每个数据上
- apply的使用场景比applymap要多
1 | # apply使用 |
结果:
1 | 0 张 |
- 获取名字
1 | # 获取名 |
结果:
1 | 0 三 |
- 结果合并
1 | # 结果合并 |
结果:
1 | 员工姓名 部门 地址 姓 名 |
分组(groupby)
- 对数据集进行分组,然后对每组进行统计分析
- pandas能利用groupby进行更加复杂的分组运算
- 分组运算
- split > apply > combine
- 拆分:进行分组的根据
- 应用:每个分组云U型的计算规则
- 合并:把每个分组的计算结果合并起来
1 | #读取数据 |
- GroupBy对象:DataFrameGroupBy,SeriesGroupBy
- GroupBy对象没有进行实际运算,只是包含分组的中间数据
- 按列名分组,obj.groupby(‘label’)
- 按列名多层分组,obj.groupby([‘label1’,’label2’]) —->多层dataframe
1 | #groupby() |
结果:
1 | <class 'pandas.core.groupby.DataFrameGroupBy'> |
- 对GroupBy对象进行分组运算/多重分组运算,如mean()
- 非数值数据不进行分组运算
1 | grouped['Happiness Score'].mean() #分组里面,happiness的平均分 |
结果:
1 | Region |
- size()返回每个分组的元素个数
1 | grouped.size() #分组里面的数量,比如澳大利亚和新西兰组里面有2个 |
结果:
1 | Region |
- Groupby对象支持迭代操作
- 每次迭代返回一个元组(group_name,group_data)
- 可用于分组数据的具体运算
1 | # 迭代groupby对象 |
结果:
1 | Australia and New Zealand地区的平均幸福指数:7.285,最高幸福指数:7.2860000000000005,最低幸福指数7.284 |
- 按自定义的函数分组
- 如果自定义函数,操作针对的是index
1 | # 自定义函数进行分组 |
结果:
1 | Country Region Happiness Score Standard Error \ |
实际项目中,通常可以先人为构造出一个分组列,然后再进行groupby
1 | # 实际项目中,通常可以先人为构造出一个分组列,然后再进行groupby |
结果:
1 | 幸福指数整数部分为2的分组数据个数:2 |
聚合(aggregation)
- grouped.agg(func),数组产生标量的过程,如mean(),count()等
- 常用于对分组后的数据进行计算
- 内置的聚合函数:sum(),mean(),max(),min(),count(),size(),describe()
- 可通过字典为每个列指定不同的操作方法
- 可自定义函数,传入agg方法中
1 | import numpy as np |
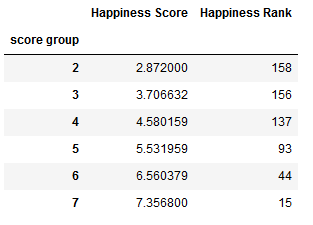
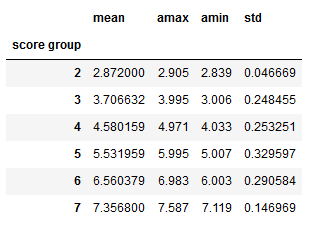
- 求各种数值(mean,最大值,最小值,方差)
1 | grouped['Happiness Score'].agg([np.mean,np.amax,np.amin,np.std]) |
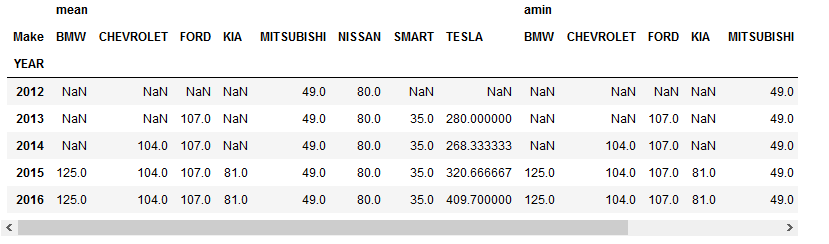
透视表
df.pivot_table(values,index,columns,aggfunc,margins)
- values:透视表中的元素值(根据聚合函数得出的)
- index:透视表的的行索引
- columns:透视表的列索引
- aggfunc:聚合函数,可以指定多个函数
- margins:表示是否对所有数据进行统计
1 | import pandas as pd |
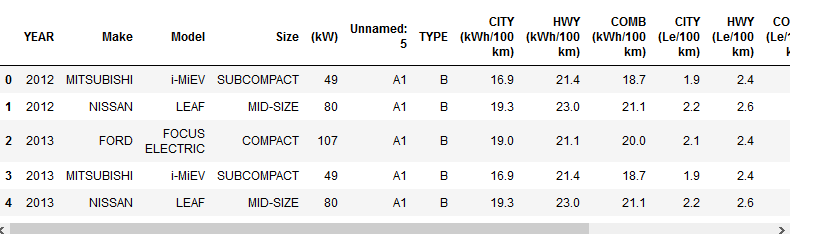
- 通过计算平均值来比较
1 | # 我们想要比较不同年份的不同厂商的车,在电池方面的不同 |
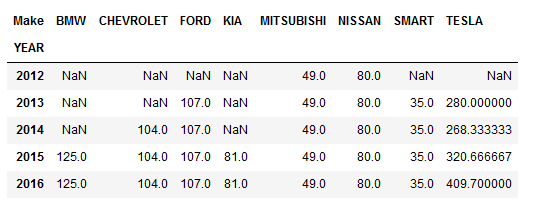
- 通过多个聚合函数来对比
1 | # 我们想要比较不同年份的不同厂商的车,在电池方面的不同 |
相关链接:源文件


