介绍
Drew Conway认为数据科学包括:
黑客技术:
- 如编程能力
- 向量化操作和算法思想
数学和统计知识
- 如常见的分布、最小二乘法
实质性的专业知识
数据科学设计到的操作 by David Donoho
- 数据探索与准备
- 数据操作、清洗等
- 数据展现形式与转化
- 不同格式的数据操作,表格型、图像、文本等
- 关于数据的计算
- 通过编程(python或R)计算分析数据
- 数据建模
- 预测、聚类等机器学习模型
- 数据可视化与展示
- 绘图、交互式、动画等
- 数据科学和涉及到的学科知识
何为数据分析
- 用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论对数据加以详细研究和概括总结的过程。
数据分析的目的
- 从数据中挖掘规律、验证猜想、进行预测
准备工作
安装Anaconda
链接:Anaconda
ps:安装anaconda的时候,把原有的python全部删了(否则会报错或者运行不了python3.x),然后安装的时候两个都勾选(务必确认勾选python添加到系统环境变量)
安装Pycharm
链接:Pycharm
ps:配置环境–>project interpreter—>选择anaconda中python的路径
Python进阶技巧
条件表达式
列表推导式
字典推导式
1 | #条件表达式 |
结果:
1 | 1.6094379124341003 |
Python常用的容器类型(list 、set、dictionary、tuple)
ps:列表、集合、字典以及元组的详细基础知识见python基础,这里讲基础没有涉及的函数以及方法。
1 | l = [1, 'a', 2, 'b'] |
结果:
1 | <class 'list'> |
1 | t = (1, 'a', 2, 'b') |
结果:
1 | <class 'tuple'> |
1 | d = {'百度': 'https://www.baidu.com/', |
结果
1 | 通过key获取value: https://www.baidu.com/ |
1 | #创建集合 |
结果:
1 | 创建set: |
Counter(类似于数学中的多重集)
链接:Counter
- 初始化 (会按照从多到少排列)
1 | import collections |
结果:
1 | Counter({'b': 3, 'a': 2, 'c': 1}) |
- update() 更新内容,注意是做“加法”,不是“替换”
1 | # 注意这里是做“加法”,不是“替换” |
结果:
1 | Counter({'a': 6, 'd': 4, 'b': 3, 'c': -1}) |
- 访问内容[key]
- 注意和dict的区别:如果Counter中不存在key值,返回0;而dict会报错
1 | print('a=', c1['a']) |
结果:
1 | a= 6 |
- element()方法
1 | for element in c1.elements(): |
结果:
1 | a |
- most_common()方法,返回前n多的数据(比如,在词频统计中,只要求最多的前三个)
1 | c1.most_common(3) |
结果:
1 | [('a', 6), ('d', 4), ('b', 3)] |
defaultdict
- 在Python中如果访问字典里不存在的键,会出现KeyError异常。有些时候,字典中每个键都存在默认值是很方便的
- defaultdict是Python内建dict类的一个子类,第一个参数为default_factory属性提供初始值,默认为None。它覆盖一个方法并添加一个可写实例变量。它的其他功能与dict相同,但会为一个不存在的键提供默认值,从而避免KeyError异常。
链接:defaultdict
1 | # 统计每个字母出现的次数 |
结果:
1 | Counter({'o': 2, 'c': 1, 'h': 1, 'i': 1, 'n': 1, 'a': 1, 'd': 1, 'p': 1}) |
- 使用dict:
1 | # 使用dict |
结果:
1 | dict_items([('c', 1), ('h', 1), ('i', 1), ('n', 1), ('a', 1), ('d', 1), ('o', 2), ('p', 1)]) |
- 使用defaultdict
1 | # 使用defaultdict |
结果:
1 | dict_items([('c', 1), ('h', 1), ('i', 1), ('n', 1), ('a', 1), ('d', 1), ('o', 2), ('p', 1)]) |
- 记录相同元素的列表
1 | # 记录相同元素的列表 |
结果:
1 | dict_items([('yellow', [1, 3]), ('blue', [2, 4]), ('red', [1])]) |
map()函数
- map(function,sequence)
- 可用于数据清洗
1 | import math |
结果:
1 | 示例1,获取两个列表对应位置上的最小值: |
匿名函数lambda
- 简单的函数操作
- 返回值是func类型
- 可结合map()完成数据清洗操作
1 | my_func = lambda a, b, c: a * b #返回值是一个函数类型 function |
结果:
1 | <function <lambda> at 0x000002B8CF089F28> |
科学计算库NumPy(Numerical Python)
- 高性能科学计算和数据分析的基础包,提供多维数组对象
- ndarray,多维数组(矩阵),具有矢量运算能力,快速、节省空间
- 矩阵运算,无需循环,可完成类似Matlab中的矢量运算
- 线性代数、随机数生成
- import numpy as np
链接: numpy_api
注: Scipy也是科学计算库
- 在Numpy库的基础上增加了众多的数学、科学及工程常用的库函数
- 线性代数、常微分方程求解、信号处理、图像处理、稀疏矩阵等
- import scipy as sp
ndarray, N维数组对象(矩阵)
- nidm属性,维度个数
- shape属性,各维度大小
- dtype属性,数据类型
1 | import numpy as np |
结果:
1 | [[2 3 4] |
创建ndarray
- np.array(collection),collection为序列型对象(list),嵌套序列(list of list)
- np.zeros,np.ones,np.empty指定大小的全0或全1数组
- 注意:第一个参数是元组,用来指定大小,如(3,4)
- empty不是总是返回全0,有时返回的是未初始的随机值
1 | import numpy as np |
结果:
1 | 列表: [1, 2, 3] |
- array的运算
1 | #array的运算 |
结果:
1 | array([-3, -3, -3]) |
- 建立ndarray数据,第三个参数是步长(step)
1 | #建立ndarray数据,第三个参数是步长(step) |
结果:
1 | [ 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28] |
- 单位矩阵等初始化
1 | print('ones:\n', np.ones((3, 2))) |
结果:
1 | ones: |
- repeat和*的区别
1 | # repeat和*的区别 |
结果:
1 | *操作: |
- 矩阵的叠加
1 | p1 = np.ones((3, 3)) |
结果:
1 | [[ 1. 1. 1.] |
3.3 Array操作
1 | print('p1: \n', p1) #p1和p2都引用了上面p1和p2 |
结果:
1 | p1: |
- 转换数组类型(astype)
1 | #数组的转置 |
结果:
1 | p3形状: (2, 3) |
- 数据类型的查看以及对数据类型的转换(astype)
1 | #数据类型的查看以及对数据类型的转换(astype) |
结果:
1 | p3数据类型: int32 |
- 对于数据基本的操作,比如求和,最小最大,平均,方差等
1 | #对于数据基本的操作,比如求和,最小最大,平均,方差等 |
结果:
1 | sum: -8 |
索引与切片
- 一维数组的索引与Python的列表索引功能相似
- 多维数组的索引
- arr[r1:r2, c1:c2]
- arr[1,1]等价arr[1][1]
- [:]代表某个维度的数据
1 | # 一维array |
结果:
1 | s: [ 0 1 4 9 16 25 36 49 64 81 100 121 144] |
- 二维array
1 | # 二维array |
结果:
1 | r: |
- 条件索引
- 布尔值多维数组 arr[condition]condition可以是多个条件组合
- 注意,多个条件组合要使用& |,而不是and or
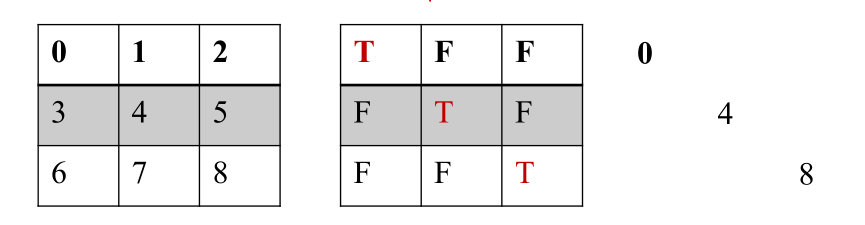
以上是根据条件将数据转换成布尔型true和false的情况,然后再把true所对应的值取出来。
1 | r > 30 #引用上面的r的数组 数据类型:bool(布尔型) |
结果:
1 | array([[False, False, False, False, False, False], |
- 数据的过滤
1 | # 过滤 |
结果:
1 | [31 32 33 34 35] |
array的拷贝操作
- arr1 = arr2
- arr1内数据的更改会影响arr2
- 建议使用arr1 = arr2.copy(),这样就不会互相影响
1 | # copy()操作 #仍然引用上面的r数组 |
结果:
1 | [[ 0 1 2 |
- 对r2赋值,查看对原数组是否会影响
1 | # 将r2内容设置为0 |
结果:
1 | [[ 0 0 0 3 4 5] |
- 通过copy操作后对r3赋值,查看对原数组是否有影响
1 | r3 = r.copy() #对r进行copy操作---->r3 |
结果:
1 | [[ 0 0 0 3 4 5] |
遍历Array
1 | t = np.random.randint(0, 10, (4, 3)) #0-10随机一个4行3列的数组 |
结果:
1 | [[5 1 9] |
- 遍历每行操作
1 | for row in t: #遍历每行 |
结果:
1 | [5 1 9] |
- 使用enumerate()
1 | # 使用enumerate() |
结果:
1 | row 0 is [5 1 9] |
- 将所有数据平方
1 | t2 = t ** 2 #将数据全部平方 |
结果:
1 | [[25 1 81] |
- 使用zip对两个array进行遍历计算
1 | # 使用zip对两个array进行遍历计算 |
结果:
1 | [5 1 9] + [25 1 81] = [30 2 90] |
- 取出唯一值
1 | a = list([1,1,1,1,1,2,2,2,2,3,3,3,4]) #取出唯一的值 |
结果:
1 | [1 2 3 4] |
相关链接:源文件


