re模块的使用
链接:正则表达式
match(正则表达式,待匹配字符串(起始位置))
- 用于正则匹配检查,如果待匹配字符串能够匹配正则表达式,则match方法返回匹配对象,否则返回None
- 采用从左往右逐项比较匹配
实例1:
1 | ##例如:新的邮箱手机号验证格式是否正确,用正则表达式对于格式验证 |
结果:
1 | <_sre.SRE_Match object; span=(0, 11), match='chinahadoop'> |
group()方法
- 用来返回字符串的匹配部分
实例2:
1 | ##例如:新的邮箱手机号验证格式是否正确,用正则表达式对于格式验证 |
结果:
1 | <_sre.SRE_Match object; span=(0, 11), match='chinahadoop'> |
字符匹配、数量表示、边界表示
单字符匹配
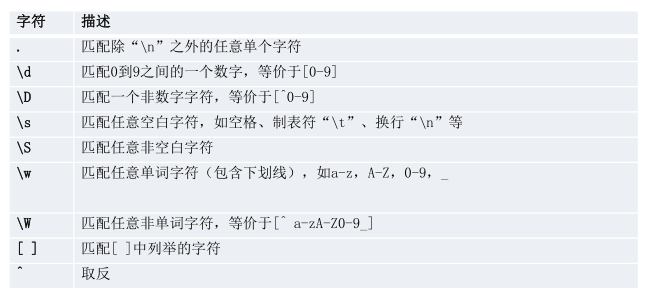
Ps: ‘\d’ ‘\s’’\w’经常使用
实例3:
1 | import re |
结果:
1 | a |
实例4:
1 | import re |
结果:
1 | <_sre.SRE_Match object; span=(0, 1), match='\t'> |
实例5:
1 | import re |
结果:
1 | <_sre.SRE_Match object; span=(0, 1), match='h'> |
多字符匹配(单字符+数量表示)
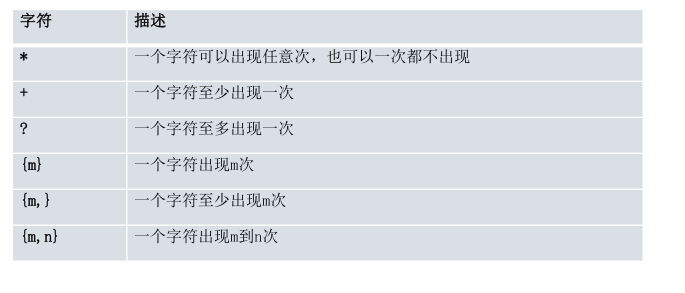
实例6:
1 | # \d只匹配数字 |
结果:
1 | 1234 |
实例7:
1 | #+至少出现一次 |
结果:
1 | None |
边界表示
字符串与单词边界

应用场景:是否要加边界,区别:比如用户注册的时候验证他输入的邮箱就要加边界,限制他写入的是合法的邮箱,再比如处理文本数据的时候提取邮箱信息,有可能文本里的数据就是非法的,只是为了提取出邮箱,就不用加边界。
实例8:
1 | #边界表示 |
结果:
1 | 13623456767 |
匹配分组

实例9:
1 | #匹配分组 |
结果:
1 | <_sre.SRE_Match object; span=(0, 3), match='100'> |
正则表达式的高级用法
search
- 从左到右在字符串的任意位置搜索第一次出现匹配给定正则表达式的字符
实例10:
1 | import re |
结果:
1 | <_sre.SRE_Match object; span=(5, 8), match='car'> |
findall
- 在字符串中查找所有匹配成功的组,返回匹配成功的结果列表
实例11:
1 | #findall |
结果:
1 | ['car', 'car', 'car', 'car'] |
finditer
- 在字符串中查找所有正则表达式匹配成功的字符串,返回iterator迭代器
实例12:
1 | #finditer |
结果:
1 | helloworld@163.com |
sub
- 将匹配到的数据使用新的数据替换
实例13:
1 | # sub |
结果:
1 | python python c cpp python |
split
- 根据指定的分隔符切割字符串,返回切割之后的列表
实例14:
1 | #split |
结果:
1 | apple=5 |
贪婪与非贪婪模式
贪婪模式
- 正则表达式引擎默认是贪婪模式,尽可能多的匹配字符
实例15:
1 | import re |
结果:
1 | ['hello12345'] |
非贪婪模式
- 与贪婪模式相反,尽可能少的匹配字符
- 在表示数量的’*’,’?’,’+’,’{m,n}’符号后面加上?,使贪婪变成非贪婪
实例16:
1 | import re |
结果:
1 | ['hello'] |


